Was ist CHAID? (Chi- Quadrat Unabhängigkeitstest)
Dieser Test soll aufzeigen, wie sich ein abhängiges Merkmal (Kredit Rückzahlung) durch Einfluss eines unabhängigen
Merkmales ( Alter der Kunden) am besten unterscheidet!
Man versucht hier die Objekte in guter und schlechter Kunde aufzuteilen um Entscheidungen z.B.
fürs Management treffen zu können!
Beispiel: Abhängiges
Merkmal: Rückzahlung; unabh. Merkmal: Alter
+ Arbeitsdauer

Alter: Knoten [18;38] Die Kunden zwischen 18 und 38
Jahren sind haben eher Probleme ihre Kredite
rechtzeitig zurück zuzahlen! Der grüne Balken ist viel größer!!! Knoten [38;43] In diesem Intervall bezahlen die
Kunden fast immer ihre Kredite zurück! Knoten [43;50] In diesem Intervall könnte die midlife- Krisis eine Rolle für die Mehrzahl an nicht
zurückgezahlten Krediten spielen Knoten [50;68] Hier werden die Kredite wieder
fast völlig zurückgezahlt! Arbeitsdauer: Hier ist die Arbeitsdauer bei der schlechten Kategorie
des Alters- Knoten [38;43] angesetzt, da man hier
einen schlechten Wert der Rückzahlung errechnet hat! Knoten [4;6;8] Man sieht hier, das in dieser
Alterskategorie die Rückzahlung der Kredite besonders schlecht ist,
während in der Kategorie [10;20]
alle Kredite zurückgezahlt werden. Was ein Grund sein kann: Wer länger
arbeitet, verdient mehr und hat auch mehr Zeit den Kredit zurück zuzahlen! Dieser Balken gibt an ca. 50% schlechte Kunden Dieser Balken gibt an ca. 50% gute Kunden
![]()
![]()
![]()

Vorgehen bei
CHAID:
Für jede der unabhängigen Merkmale wird überprüft, ob sich die Menge der Objekte anhand dieses
Merkmals sehr gut separieren lässt (bezogen auf das abhängige Merkmal).
Wir
nehmen das Beispiel der Seite 1 und gehen es Schritt für Schritt durch!
Beschreibung: Der Chef einer Bank möchte wissen wie
er seine zukünftigen Entscheidungen
bezüglich „schlechte und guter
Kunden“ bei der Rückzahlung von Krediten , besser
treffen kann!
Man entscheidet sich als
erstes für das Geschlecht als unabhängiges Merkmal.
Schritt 1:
Um zu überprüfen ob es überhaupt einen Zusammenhang zwischen den beiden Variablen
gibt, was sehr sinnvoll wäre, benutzen wir hier nicht die Korrelation (Die Korrelation
vergleicht strenggenommen nur metrische Werte), sondern die Kreuztabelle!
Datendatei = kredit_bereinigt.sav
Exkurs: Kreuztabelle




Nachdem wir die Variablen eingetragen und die
Einstellungen vorgenommen haben,
können wir nun die Ergebnisse, die uns SPSS liefert
interpretieren!
Interpretation der Kreuztabelle:
(Rückzahlung * Geschlecht)
Chi-Quadrat-Tests
|
|
Wert |
df |
Asymptotische Signifikanz (2-seitig) |
|
Chi-Quadrat nach Pearson |
|
|
|
|
|
,250 |
1 |
,617 |
0 Zellen (,0%) haben eine erwartete Häufigkeit kleiner 5.
Die minimale erwartete Häufigkeit ist 14,85.
ACHTUNG:
Der CHI- Quadrat- Test
ist nur sinnvoll, wenn mehr als 5 Werte in einer Spalte vorkommen!

Gehen wir hier kurz auf den Test ein:
Thesen: H0: Merkmale unabhängig (Rückzahlung hat nichts
mit dem Alter zutun)
H1: Merkmale abhängig (Rückzahlung hat was mit dem Alter zutun)
Errechnen wir uns die Wahrscheinlichkeit, das das Geschlecht „männlich“ ist und der Kredit zurückgezahlt wird!
![]()
Das ein Kunde männlich ist und einen Kredit zurückzahlt kommt
also mit 35,1 % Wahrscheinlichkeit vor!
Was wird hier getestet?
1. Wir errechnen einen Chi- Quadrat-Wert für unsere Stichprobe von 0,250. Um nun eine
Entscheidung treffen zu können, müssen wir uns für ein Signifikanzniveau entscheiden.
2. Legen wir dieses mal auf 0,05 fest. D.H. durch ablesen des Chi- Quadrat- Wertes, bei einem
Freiheitsgrad von 1und 1-0,05 Signifikanzniveau bekommen wir den Wert = 3,841.
3. Dieser Wert besagt, das sich der Test im Intervall von 0 bis 3,841 für H0 entscheidet und ab
3,8412 für H1 entscheidet. Wie in der folgenden Formel zu sehen.

Wir
haben hier zwei Werte, die wir uns näher anschauen sollten.
1. Den Wert 0,250 der auch als T-Wert bezeichnet wird
2. Den Wert 0,617 der die Signifikanz darstellt
Schauen wir uns nun den Test selbst an:

r = Zeilenanzahl
s = Spaltenanzahl
Auf unser Beispiel bezogen:
r = wir haben in obiger Tabelle 2 Zeilen
s = wir haben in obiger Tabelle 2 Spalten
T
= der T-Wert = 0,250 (Der
errechnete Test-Wert,wo die Entscheidung zwischen H0
und H1 kippt)
a =
0,05 (Dies ist nicht von SPSS vorgegeben, sondern
so festgelegt)
Nun einsetzen:

![]()
Diesen Wert müssen wir jetzt aus der Tabelle
auslesen
- Wir haben (2-1)*(2-1) = 1
Freiheitsgerade
- 1-0,05 = 0,95 = a
Das
ergibt ein c2
von 3,841
0,250 < 3,841 ® H0
Das ist nicht nach
der Methode der Vorlesung berechnet, da hier ein a von 0,05
angenommen wurde!
Möchte man die Signifikanz zu dem T-Wert
per Hand errechnen, so geht man
folgendermaßen vor:
Wie schon oben
angegeben, haben wir den T-Wert von 0,250 und
dazu errechnet SPSS die Signifikanz von
0,617
Wie
errechnet man nun diesen Signifikanzwert?
Im vorangegangenen Beispiel hatten wir die Freiheitsgrade mit 1
bestimmt, was sich nicht verändert hat.
Nun haben wir den Wert von 0,250 als Chi-Quadrat
Wert und suchen dazu die Signifikanz!
Schauen wir uns dazu die Tabelle der Chi-
Quadrat- Verteilung an:
![]()
![]()

Nun
sieht man in der obigen Tabelle, in der Reihe der Freiheitsgrade = 1, das der Chi- Quadrat- Wert, den SPSS
errechnet
hat, zwischen zwei Werten liegt.
0,00158 und 2,706
und diese Werte zu den g (1- a) von
0,9 = 2,706
0,1 = 0,00158
gehören.
Man sucht den Wert von g, wo man ein Chi- Quadrat von 0,25 hat.
Der Wert ist hier 0,383 und rechnet man nun 1- 0,383, so erhält man 0,617!
NICHT KLAUSUR RELEVANT!!!
Auf das Beispiel bezogen kommen wir nun zum Ergebnis:
Der Signifikanzwert von 0,617 sagt aus, das die
Irrtumswahrscheinlichkeit 61,7% groß ist, das man sich für eine
stochastische Abhängigkeit entscheidet. Diese Irrtumswahrscheinlichkeit
ist viel zu hoch und aus diesem Grund
kann H0 nicht verworfen werden, das aussagt, das dieses Merkmal
stochastisch unabhängig ist!
Das Geschlecht hat keinen Einfluss auf die
Rückzahlung der Kredite!
Nächster Versuch: Das Alter
Beim Alter taucht das Problem auf, das es sich hier um prinzipiell metrische skalierte Werte handelt und bei
einer großen Datenmenge völlig unübersichtliche Bäume ergeben werden.
Man
muss also die Werte klassieren: Hier
etwa ca ![]() Klassen = 10 Klassen
Klassen = 10 Klassen
[18;22], [22;27], [27;31], [31;33], [33;38], [38;43], 43;50], [50;59], [59;68]
mit
in etwa gleich vielen Stichproben Elementen!
Aber
selbst hier werden die Bäume noch zu unübersichtlich dargestellt!
Wichtig: Man versucht nun mehrere Klassen zu einer Kategorie
zusammen zufassen, bei denen keine signifikanten Unterschiede bezogen auf
das abhängige Merkmal (Rückzahlung) bestehen. Man sucht hier Klassen,
die sich gut Unterscheiden, damit man auch eine Entscheidung treffen kann.
Teilt sich die abhängige Variable in „gut und Schlecht“ so sollen auch die
Klassen der unabhängigen Variablen dies gut unterscheiden! -
Auch hier wird ein Signifikanzniveau von
0,05 selbst vorgegeben! -
Natürlich fasst man hier nur solche
Klassen zusammen, die auch nebeneinander liegen.
Unser Beispiel:
Nimmt man hier die ersten beiden Intervalle und untersucht, ob sie sich signifikant bzgl. Der Rückzahlung
unterscheiden, so erhält man folgende Tabelle:
![]()
![]()
![]()
![]()

Um auf die erwartete Anzahl zu kommen errechnet man:
![]()
Chi-Quadrat-Tests
|
|
Wert |
df |
Asymptotische Signifikanz (2-seitig) |
|
Chi-Quadrat nach Pearson |
|
|
|
|
|
,023 |
1 |
,879 |
d.h. es macht keinen Sinn, diese beiden Klassen beizubehalten, da sie sich bzgl. Des Merkmals Rückzahlung nicht signifikant
unterscheiden. Bei CHAID werden aber im ersten Schritt alle Klassen betrachtet, die in Frage kommen könnten und die
beiden zusammengefasst, die den höchsten Signifikanzwert haben.
Schritt a:
|
Kategorie 1 |
Kategorie 2 |
Chi- Quadrat- Wert |
Signifikanz |
|
|
|
|
|
|
|
|
18;22 |
22;27 |
0,023 |
0,879 |
schlecht |
|
22;27 |
27;31 |
2,329 |
0,127 |
|
|
27;31 |
31;33 |
1,698 |
0,193 |
|
|
31;33 |
33;38 |
1,698 |
0,193 |
|
|
33;38 |
38;43 |
18,333 |
0,000 |
gut |
|
38;43 |
43;50 |
6,7669 |
0,009 |
|
|
43;50 |
50;59 |
7,287 |
0,007 |
|
|
50;59 |
59;68 |
1,81 |
0,179 |
|
Man sieht also, dass die ersten beiden Intervalle sich am
wenigsten unterscheiden und deshalb
zusammen gefasst werden können!
|
Kategorie 1 |
Kategorie 2 |
Chi- Quadrat- Wert |
Signifikanz |
|
|
|
|
|
|
|
|
18;27 |
27;31 |
2,523 |
0,112 |
|
|
27;31 |
31;33 |
1,698 |
0,193 |
schlecht |
|
31;33 |
33;38 |
1,698 |
0,193 |
|
|
33;38 |
38;43 |
18,333 |
0,000 |
gut |
|
38;43 |
43;50 |
6,7669 |
0,009 |
|
|
43;50 |
50;59 |
7,287 |
0,007 |
|
|
50;59 |
59;68 |
1,81 |
0,179 |
|
Jetzt werden die Intervalle [27;31]
und [31;33] zusammengefasst!!!
|
Kategorie 1 |
Kategorie 2 |
Chi- Quadrat- Wert |
Signifikanz |
|
|
|
|
|
|
|
|
18;27 |
27;33 |
1,142 |
0,285 |
|
|
27;33 |
33;38 |
0,732 |
0,392 |
schlecht |
|
33;38 |
38;43 |
18,333 |
0,000 |
gut |
|
38;43 |
43;50 |
6,7669 |
0,009 |
|
|
43;50 |
50;59 |
7,287 |
0,007 |
|
|
50;59 |
59;68 |
1,81 |
0,179 |
|
Jetzt werden die Intervalle [27;33]
und [33;38] zusammengefasst!!!
|
Kategorie 1 |
Kategorie 2 |
Chi- Quadrat- Wert |
Signifikanz |
|
|
|
|
|
|
|
|
18;27 |
27;38 |
2,358 |
0,125 |
|
|
27;38 |
38;43 |
24,662 |
0,000 |
gut |
|
38;43 |
43;50 |
6,7669 |
0,009 |
|
|
43;50 |
50;59 |
7,287 |
0,007 |
|
|
50;59 |
59;68 |
1,81 |
0,179 |
schlecht |
Jetzt werden die Intervalle [50;59]
und [59;68] zusammengefasst!!!
Bevor dies durchgeführt wird, müssen wir noch etwas beachten!
Die Intervalle [27;31], [31;33] und [33;38] wurden zusammengefasst, es sind aber nur
[27;31] gegen [31;33] und [27;33] gegen [33;38] getestet worden. Es fehlt also noch der Test zwischen
[27;31] und [31;38]!!!
Es sollte sich hier eine hohe Signifikanz herausstellen, damit
man auch diese Intervalle zusammen
führen kann!!!

Chi-Quadrat-Tests
|
|
Wert |
df |
Asymptotische Signifikanz (2-seitig) |
|
Chi-Quadrat nach Pearson |
|
|
|
|
|
,059 |
1 |
,809 |
Wie erhofft haben wir eine große Signifikanz und können nun auch die Klassen so lassen wie wir es vorher
angenommen haben!
Jetzt werden die Intervalle [50;59]
und [59;68] zusammengefasst!!!
|
Kategorie 1 |
Kategorie 2 |
Chi- Quadrat- Wert |
Signifikanz |
|
|
|
|
|
|
|
|
18;27 |
27;38 |
2,358 |
0,125 |
schlecht |
|
27;38 |
38;43 |
24,662 |
0,000 |
gut |
|
38;43 |
43;50 |
6,7669 |
0,009 |
gut |
|
43;50 |
59;68 |
7,552 |
0,006 |
gut |
Jetzt müssen wir noch die ersten beiden Intervalle zusammenführen, allerdings auch wieder aufpassen, da hier wieder
mehrere Intervalle zusammengeführt werden!
Die Intervalle [18;22] bis [33;38] wurden zusammengefasst, es sind aber nur
[18;22] gegen [22;27] und [27;31] alle bis gegen [33;38] getestet worden. Es fehlt also noch der Test zwischen
[18;27] und [27;31]!!!
Es sollte sich hier eine hohe Signifikanz herausstellen,
damit man auch diese Intervalle zusammen führen kann!!!

Chi-Quadrat-Tests
|
|
Wert |
df |
Asymptotische Signifikanz (2-seitig) |
|
Chi-Quadrat nach Pearson |
|
|
|
|
|
1,329 |
1 |
,249 |
Dieser Wert ist auch ein
Hinweis dafür, das wir die Intervalle zusammenlassen
können!
Jetzt werden die Intervalle [18;27]
und [27;38] zusammengefasst!!!
|
Kategorie 1 |
Kategorie 2 |
Chi- Quadrat- Wert |
Signifikanz |
|
|
|
|
|
|
|
|
18;38 |
38;43 |
22,032 |
0,000 |
gut |
|
38;43 |
43;50 |
6,7669 |
0,009 |
gut |
|
43;50 |
59;68 |
7,552 |
0,006 |
gut |
Übrig bleiben nun die Unterteilungen, wie im Baum zu sehen sind!
Berechnen dieses
Beispieles mit Answer Tree
Schritt 1 Projekt anlagen


Auswählen der Datendatei kredit_bereinigt.sav

Das Projekt kann hier noch umbenannt werden und dann auf das Symbol des Baumes klicken

CHAID mit Weiter bestätigen

Die abhängige Variable in das Feld Ziel eintragen und das Feld Prediktoren frei lassen, damit er alle Variablen
übernimmt (es sind nach der Auswahl der abhängigen Variablen alle Anderen unabhängig)

Auf erweiterte Optionen klicken

Diese Einstellungen vornehmen, damit man einen Baum auf mehrere Ebenen erweitern kann. Alles weitere
steht in der Hilfe! OK und dann auf Fertigstellen und man erhält den root- Knoten!

Mit rechtem Mausklick kann man nun „Prediktor auswählen“. D.h. das man die abhängige Variable durch eine
unabhängige Variable erklären lassen kann.

Nachdem man das Alter ausgewählt hat, kann man sich noch anschauen, wie das Programm die Intervalle in
Kategorien
zusammenfasst! „Trennung
definieren“

Hier sieht man nun, das die Werte
hier automatisch berechnet werden. Mit Weiter bestätigen und auf Aufbau
und man erhält den dazugehörigen Baum!
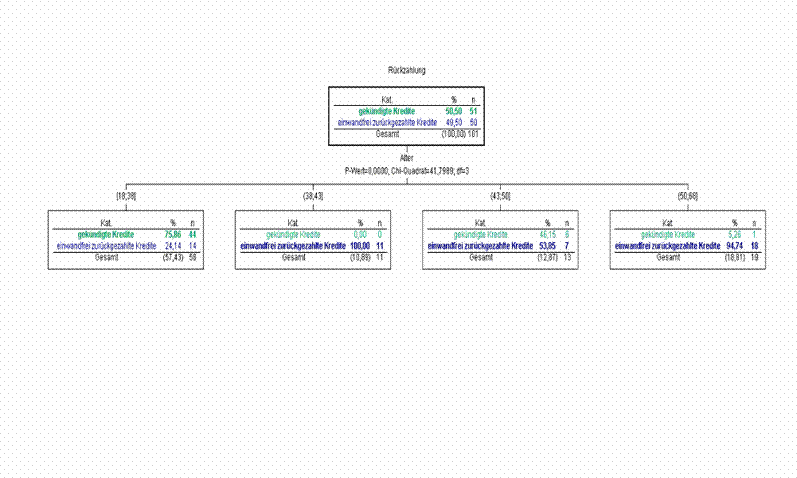
Um nun auf das Anfangsbeispiel einzugehen, wollen wir wissen,
was die „Arbeitsdauer in Jahren“ uns zum Knoten
[38;43] zu sagen hat! Hier gehen wir
wie in den letzten beiden Schritten vor und wählen den Knoten und dann
Prediktoren auswählen usw.

Wir können die Erstellung der Kategorie noch über eine andere Methode überprüfen:
(Bonferroni Anpassung)
Bildet
man eine Kreuztabelle mit den zuvor errechneten Werten erhält man folgendes:


Bildet
man nun eine Kreuztabelle mit den ursprünglichen Klassen erhält man folgendes:


Man sieht bei beiden Kreuztabellen, das eine sehr kleine Signifikanz heraus kommt. Aber,
0,00000001580 ist um
ein vielfaches kleiner
als 0,0000003030 und deshalb ist die erste Kreuztabelle die richtig Lösung für
die Variable Alter!
Gewinnübersicht
Zielvariable: Rückzahlung Zielkategorie: einwandfrei zurückgezahlte Kredite
Statistiken
Knoten Knoten: Anzahl % Knoten: Fälle: Anzahl% Gewinn (%) Index (%)
2 11 10,89 11 22,00 100,00000 202,00000
6 6 5,94 6 12,00 100,00000 202,00000
4 19 18,81 18 36,00 94,73684 191,36842
1 58 57,43 14 28,00 24,13793 48,75862
5 7 6,93 1 2,00 14,28571 28,85714
1.Spalte Baumübersicht der Knoten

2. Spalte Anzahl in diesem Knoten bezogen auf die gesamte Stichprobe (die 3. Spalte die %)
4.
Spalte Anzahl der Fälle in diesem Knoten,
die den Kredit zurückgezahlt haben
5. Spalte Anzahl an
zurückgezahlten Krediten an der Gesamtstichprobe
6. Spalte Man sieht
hier, das es sich lohnt neue Kunden aus den Knoten 2,6 und 4 zu werben!
7. Spalte Der Index
misst die durchschnittliche Trefferquote für einen Knoten bezogen auf die
durchschnittliche
Trefferquote aller Fälle!
Beispiel: Knoten
6: Insgesamt sind unter den ganzen
Fällen ein Anteil von 50/101
das ist
0,4950495 mit einwandfrei zurückgezahlten Krediten; in dieser Klasse hat
man einen Antel
von 0,9473684; das Verhältnis von 0,9473684 zu 0,4950495 ist
gerade 1,9136842....
Durchschnittlicher Nutzen:
Würde man wissen, das durch einen gekündigten Kredit 2000DM
Verlust und durch einen zurückbezahlten
Kredit 5000DM Gewinn gemacht werden können, kann man sich dies
über zwei Einstellungen anschauen!
Man befindet sich unter „Gewinne“ und unter Menüpunkt „Format
– Gewinne“ stellt man „Durchschnittlicher
Nutzen ein“, danach unter „Analyse – Nutzen“ gibt man für
gekündigte Kredite 2000 und bei zurückgezahlten
Krediten 5000 ein!
Gewinnübersicht
Zielvariable:
Rückzahlung
Statistiken
Knoten Knoten:
Anzahl Knoten: %
Gewinn Index (%)
2 11 10,89 5000,00 341,22
6 6 5,94 5000,00 341,22
4 19 18,81 4631,58 316,07
1 58 57,43 -310,34 -21,18
5 7 6,93 -1000,00 -68,24
Hier sieht man, das die Kategorien 1
und 5 nicht lohnenswert sind!
Fehlklassifizierungsmatrix
Unter Risiko
Fehlklassifizierungsmatrix
Tatsächliche Kategorie
gekündigte
Kredite einwandfrei zurückgezahlte
Kredite Gesamt
Vorhergesagte
Kategorie
gekündigte
Kredite 50 15 65
einwandfrei
zurückgezahlte
Kredite 1 35 36
Gesamt 51 50 101
Resubstitution
Risikoschätzung 0,158416
Std.f. der
Risikoschätzung 0,0363318
![]()